




Object-Oriented Programming
Week 0
NameSpace
假设这样一种情况,当一个班上有两个名叫 Zara 的学生时,为了明确区分它们,我们在使用名字之外,不得不使用一些额外的信息,比如他们的家庭住址,或者他们父母的名字等等。
同样的情况也出现在 C++ 应用程序中。例如,您可能会写一个名为 xyz() 的函数,在另一个可用的库中也存在一个相同的函数 xyz()。这样,编译器就无法判断您所使用的是哪一个 xyz() 函数。
因此,引入了命名空间这个概念,专门用于解决上面的问题,它可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
Define a Namespace
namespace namespace_name {
// 代码声明
}
为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称,如下所示:
name::code; // code 可以是变量或函数
A Real Example
#include <iostream>
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Inside first_space
Inside second_space
NameSpace Nested
命名空间可以嵌套,您可以在一个命名空间中定义另一个命名空间。同时,命名空间中的变量与全局变量也有关系。
关于命名空间内变量和函数及全局变量的使用和作用域:
#include <iostream>
using namespace std;
namespace A
{
int a = 100;
namespace B //嵌套一个命名空间B
{
int a =20;
}
}
int a = 200;//定义一个全局变量
int main(int argc, char *argv[])
{
cout <<"A::a ="<< A::a << endl;
cout <<"A::B::a ="<<A::B::a << endl;
cout <<"a ="<<a << endl;
cout <<"::a ="<<::a << endl;
int a = 30;
cout <<"a ="<<a << endl;
cout <<"::a ="<<::a << endl;
return 0;
}
结果:
A::a =100
A::B::a =20
a =200 //全局变量a
::a =200
a =30 //局部变量a
::a =200
即:全局变量 a 表达为 ::a,用于当有同名的局部变量时来区别两者。
String
The String Class
- You must add this at the head of you code
#include <string> - Define variable of string like other types
string str = “Hello”; - Read and write string with cin/cout
cin >> str; cout << str;
Assignment For String
In C:
char charr1[20];
char charr2[20]="jungle";
charr1 = charr2; (赋值,ILLEGAL IN C!)
In C++
string str1;
string str2="lingo";
str1 = str2;(LEGAL IN C++)
Concatenation For String
string str3;
str3 = str1 + str2;
str1 += str2;
str1 += “lalala”;
Ctors
File I/O
write to file
File1<<“Hello world”<<std::endl;
File1<<“Hello world”<<std::endl;
read from file
#include <ofstream>
ifstream File2(“C:\\test.txt”);
std::string str;
File1>>str;
Note:
>>:read
<<:write
文件操作与屏幕操作一致
Memory Model
Local Vars & Global Vars
int i;// global vars.
string str;
static int j; //static global vars.
f() {
int k; // local vars.
static l; // static local
int *p = malloc(sizeof(int)); //allocated vars.
}
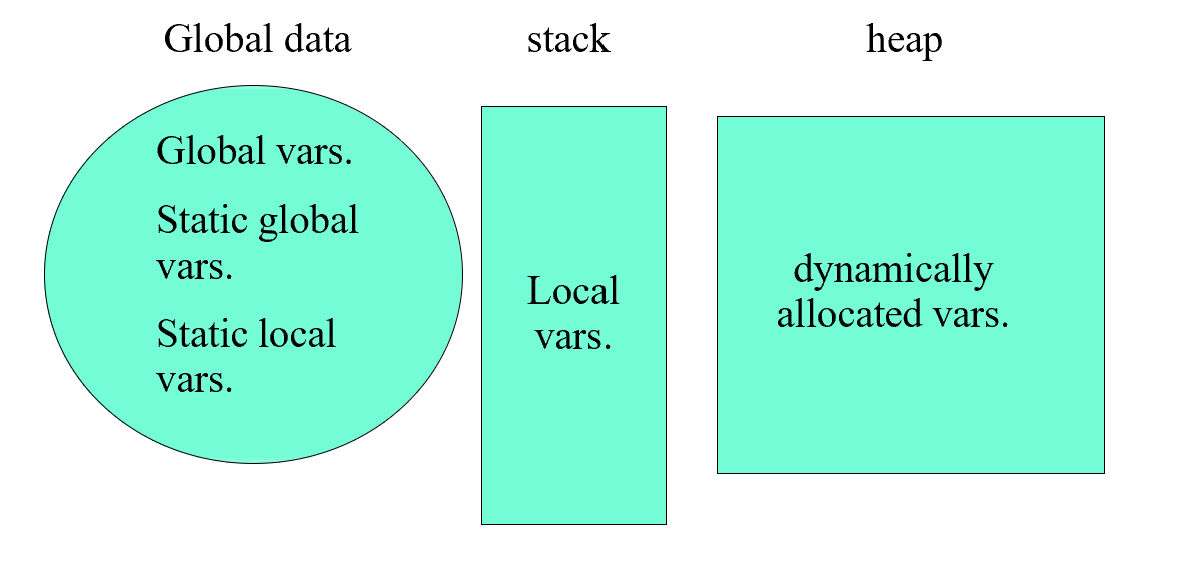
Global Vars
- vars defined outside any functions
- can be shared btw .cpp files
extern关键词可以使变量在多个cpp文件中共享
Static
- static global variable inhibits access from outside the
.cppfile - so as the static function
- static local variable keeps value btw visit to the function
- is to be initialized at its first access
- for global stuff: access restriction
- for local stuff: persistence
Week 1
Pointers to Objects
Declaration
string s = “hello”
string* ps = &s;
Get Adress
&: get address
ps = &s;
Get the Object
*: get the object
(*ps).length()
Call the Function
->:call the function
ps->length();
Access the Pointer(初始化)
string s;//s is the object itself,是指针,而且指向一块实际区域
string *ps;//ps is a pointer to an object,只是一个指针,没有实际地址
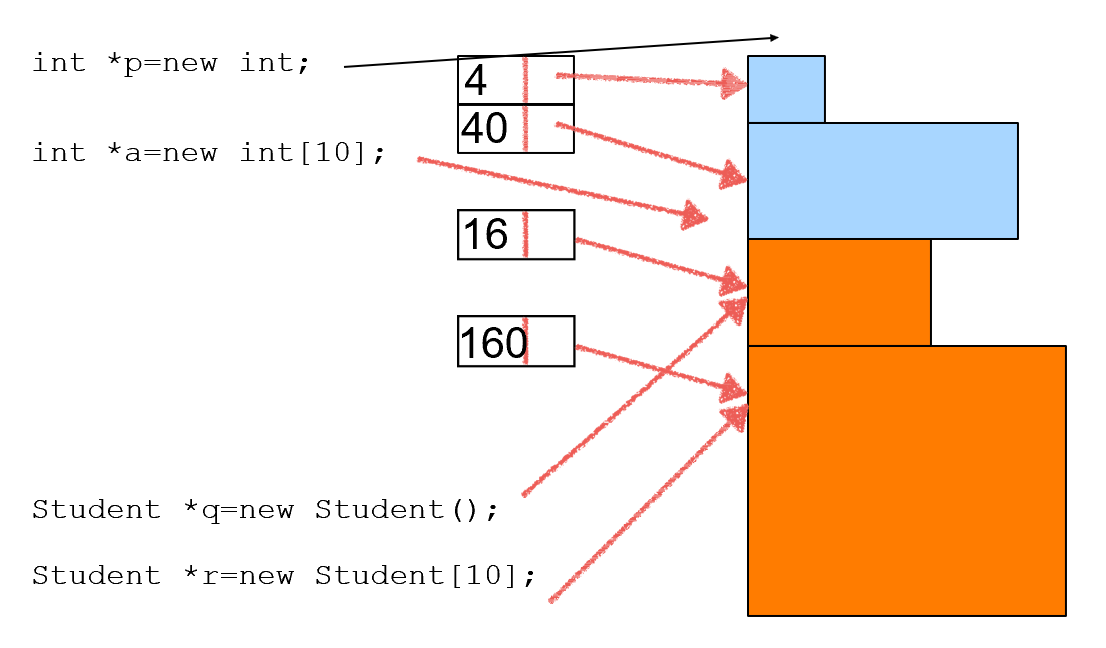
Dynamically Allocated Memory
- new
new int; new Stash;//Stash本身是一个变量类型 new int[10]new在C++中是一个操作符,后面跟的是变量类型 - delete
用delete p; delete[] p;p=new int[10]分配,必须用delete[] p删除
new is the way to allocate memory as a program runs. Pointers become the only access to that memory.
delete enables you to return memory to the memory pool when you are finished with it.
int * psome = new int [10];
The new operator returns the address of the first element of the block.
delete [] psome;
The presence of the brackets tells the program that it should free the whole array, not just the element.
若不写[]只会删除一个大小的变量,比如只删除一个四位大小的int[0]其他部分都不会被释放,造成内存泄漏
The New-delete Mech
Use delete (no brackets) if you used new to allocate a single entity.
It’s safe to apply delete to the null pointer (nothing happens).
Use delete [] if you used new [] to allocate an array.
Don’t use delete to free the same block of memory twice in succession.
Don’t use delete to free memory that new didn’t allocate.
Reference
References are a new data type in C++
char c; // a character
char* p = &c; // a pointer to a character
char& r = c; // a reference to a character
Local or global variables:
type& refname = name;For ordinary variables, the initial value is required.
被引用对象必须初始化,即等号后面的变量需要被初始化,不能是表达式。In parameter lists and member variables.
被引用对象在变量列表中,可以不打等号。type& refname
A Little Test
#include <iostream>
#include <string>
using namespace std;
int main(){
string x="This is a test for reference 1";
string &rx=x;
string y="This is a test for reference 2";
string &ry=y;
rx=ry;
cout << rx+'\n';
cout << ry+'\n';
cout << x+'\n';
cout << y+'\n';
}
输出:
This is a test for reference 2
This is a test for reference 2
This is a test for reference 2
This is a test for reference 2
可以看到,引用是原变量的引用,一旦申明后地址不可更改,他就是直接代表原变量,对他的所有操作都是对原变量的操作。
引用有什么好处?
- 1.引用是原变量的别名,可以直接对原变量进行操作,不需要再写一遍变量名。
- 2.引用传参,可以直接对原变量进行操作,如果直接传参,那么函数内部的操作只是对形参(函数内部拷贝后的新变量)的操作,不会对原变量产生影响。
- 3.引用可以作为函数的返回值,可以直接返回原变量,而不是返回原变量的拷贝。
Bindings don’t change at run time, unlike pointers.
The target of a reference must have a location!
即reference绑定的部分必须是一个变量,不能是表达式,如:
int x& =3*i;//错误的, Warning or error!
Restrictions
- No references to references
- No pointers to references
int&* p;// illegal - Reference to pointer is ok
void f(int*& p); - No arrays of references
- 不能有对引用的引用
- 不能有引用的指针
- 不能有引用的数组
- 但可以有对指针的引用
Reference VS Pointer
References
- can’t be null
- are dependent on an existing variable, they are an alias for an variable
- can’t change to a new “address” location
Pointer
- can be set to null
- pointer is independent of existing objects
- can change to point to a different address
Const
Const is declares a variable to have a constant value.
const int x = 123;
x = 27; // illegal!
x++; // illegal!
int y = x; // Ok,copy const to non-const
const int z = y; //ok, const is safer(注意这时z在初始化)
Constants are variables
- Observe scoping rules.
- Declared with “const” type modifier.
A const in C++ defaults to internal linkage
- the compiler tries to avoid creating storage for a const.
- holds the value in its symbol table.
- extern forces storage to be allocated.
只有在extern情况下常量类型才会被分配内存。const int bufsize = 1024; /*IN ANOTHER FILE*/ extern const int bufsize;Run-time Const
```C++
const int class_size = 12;
int finalGrade[class_size];//ok
//This is COMPILE CONST⬆
//The Next is Run-time Const⬇
int x;
cin >> x;
const int size = x;
double classAverage[size];//Error!
运行时常量不能直接使用
It’s possible to use const for aggregates, but storage will be allocated. In these situations, const means “**a piece of storage that cannot be changed.**” However, the value **cannot** be used **at compile time** because the compiler is not required to know the contents of the storage at compile time.
```C++
const int i[] = { 1, 2, 3, 4 };
float f[i[3]]; // Illegal struct S { int i, j; };
//(即常量数组一旦申明结束,内部所有值都不能更改)
const S s[] = { { 1, 2 }, { 3, 4 } };
double d[s[1].j]; // Illegal
//(编译器不能知道内存中的内容,即常量数组也不能直接调用)
Const and Pointer
char * const q = 'abc';//q is a const
*q = 'c';//OK
q++;//ERROR,即q指针指向的对象不能改
const char *p = 'ABC';//*p is a const
*p = 'b';//ERROR (*p) is the const,即p指向的对象不能改
你可以用const_cast关键字来要求编译器以非常量来对待常量变量,即修改其中的值。
const右边可以是表达式,与reference不同。
This Pointer
this 是 C++ 中的一个关键字,也是一个 const指针,它指向当前对象,通过它可以访问当前对象的所有成员。
this is a hidden parameter for all member functions, with the type of the struct.
void Stash::initialize(int sz)
➔ (can be regarded as)
void Stash::initialize(Stash*this, int sz)
所谓当前对象,是指正在使用的对象。
void Student::setname(char *name){
this->name = name;
}
这里的this就是指代Student这个类
Week 2
Class
类中函数第一个变量一定要是数据结构。
Definition
class Point {
public:
void init(int x,int y);
void move(int dx,int dy);
void print() const;
private:
int x;
int y;
};
封装:内部对象不可访问
Implementation
void Point::init(int x,int y){
x = ix; y = iy;
}
void Point::move(int dx,int dy){
x+= dx; y+= dy;
}
void Point::print()
const {
cout << x <<' '<< y << endl;
}
Reslover
类中的函数前面要加上<Class Name><Class Name>::<function name>:类中的function::<function name>:公共function
An Example of a Class
class student{
public:
void PrintScore();
void PrintName();
student(string inname,int inscore[]);
private:
string name;
int score[3];
};
void student::PrintScore(){
double sum=0;
for(int i=0;i<3;i++){
sum+=this->score[i];
cout<<this->score[i];
cout<<'\t';
}
cout<<sum/3;
}
void student::PrintName(){
cout<<this->name<<"\t";
}
student::student(string inname,int inscore[]){
this->name=inname;
for(int i=0;i<3;i++){
this->score[i]=inscore[i];
}
}
Stash
Container
- Container is an object that holds other objects.
- For most kinds of containers, the common interface is put() and get().
- Stash is a container that stores objects and can be expanded during running.
Implementation
- Typeless container.
- Stores objects of the same type:
— Initialized w/ the size of the type
— Doesn’t care the type but the size - add() and fetch()
- Expanded when needed
Example
struct Stash {
int size; // Size of each space
int quantity; // Number of storage spaces
int next; // Next empty space
// Dynamically allocated array of bytes:
unsigned char* storage;
void inflate(int increase);
public:
void initialize(int size);
void cleanup();
int add(void* element);
void* fetch(int index);
int count();
};
Difference between Struct and Class
struct中,只有public关键字中的内容可以访问,其他对于缺省项(private)内部均不可访问!比如,Stash.size就是非法的。
默认访问权限:struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的。
Class Constructor and Destructor
类的构造函数(Constructor)是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。
如果一个类有构造函数定义,那么编译器会在对象创立的时候自动调用
Constructor
不带参数的构造函数
下面的实例有助于更好地理解构造函数的概念:
class Line
{
public:
void setLength( double len );
double getLength( void );
Line(); // 这是构造函数
private:
double length;
};
// 成员函数定义,包括构造函数
Line::Line(void)
{
cout << "Object is being created" << endl;
}
void Line::setLength( double len )
{
length = len;
}
double Line::getLength( void )
{
return length;
}
// 程序的主函数
int main( )
{
Line line;
// 设置长度
line.setLength(6.0);
cout << "Length of line : " << line.getLength() <<endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Object is being created(编译器自动在创建变量时调用)
Length of line : 6
带参数的构造函数
默认的构造函数没有任何参数,但如果需要,构造函数也可以带有参数。这样在创建对象时就会给对象赋初始值,如下面的例子所示:
class Line
{
public:
void setLength( double len );
double getLength( void );
Line(double len); // 这是构造函数
private:
double length;
};
// 成员函数定义,包括构造函数
Line::Line( double len)
{
cout << "Object is being created, length = " << len << endl;
length = len;
}
/*......*/
int main( )
{
Line line(10.0);//声明变量时要加参数
// 获取默认设置的长度
cout << "Length of line : " << line.getLength() <<endl;
// 再次设置长度
line.setLength(6.0);
cout << "Length of line : " << line.getLength() <<endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Object is being created, length = 10
Length of line : 10
Length of line : 6
使用初始化列表来初始化字段
使用初始化列表来初始化字段:
Line::Line( double len): length(len)
{
cout << "Object is being created, length = " << len << endl;
}
上面的语法等同于如下语法:
Line::Line( double len)
{
length = len;
cout << "Object is being created, length = " << len << endl;
}
假设有一个类 C,具有多个字段 X、Y、Z 等需要进行初始化,同理地,您可以使用上面的语法,只需要在不同的字段使用逗号进行分隔,如下所示:
C::C( double a, double b, double c): X(a), Y(b), Z(c)
{
....
}
类的析构函数
类的析构函数(Destructor)是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行。
析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
下面的实例有助于更好地理解析构函数的概念:
class Line
{
public:
void setLength( double len );
double getLength( void );
Line(); // 这是构造函数声明
~Line(); // 这是析构函数声明
private:
double length;
};
// 成员函数定义,包括构造函数
Line::Line(void)
{
cout << "Object is being created" << endl;
}
Line::~Line(void)
{
cout << "Object is being deleted" << endl;
}
void Line::setLength( double len )
{
length = len;
}
double Line::getLength( void )
{
return length;
}
// 程序的主函数
int main( )
{
Line line;
// 设置长度
line.setLength(6.0);
cout << "Length of line : " << line.getLength() <<endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Object is being created
Length of line : 6
Object is being deleted
也就是说,析构函数不需要编程者主动调用,编译器会对它隐式调用。
程序员随意地调用析构函数可能还会造成错误。
#Progarm Once and #Ifndef
作用都是为了避免同一个被 #include 多次,或者避免头文件嵌套包含(参照前置声明的笔记)。需要特别注意的是:
#pragma once并不是C++的原生语法,而是编译器的一种支持,所以并不是所有的编译器都能够支持。#ifndef 则为C++的标准。#ifndef依赖于不重复的宏名称,保证了包含在#endif的内容不会被重复包含,这个内容可以是一个文件的所有内容,或者仅仅是一段代码。而#pragma once则是针对物理文件的一个标记,标记该文件不会被#include多次,不能只针对文件中某段代码进行标记。而且,#pragma once不能保证多个文件的拷贝不会被重复包含,但这种错误更容易发现,且#pragma once大大提高了编译效率。一般建议用
#pragma once,因为一个类声明和定义各占用一个物理文件,即使类声明之外的内容,也应该是和该类有关,比如非模板类中声明了模板接口,则需要在同一个文件定义该模板接口。
Week 3
Object Interactive
goto
goto 语句允许把控制无条件转移到同一函数内的被标记的语句。
注意 :在任何编程语言中,都不建议使用 goto 语句。因为它使得程序的控制流难以跟踪,使程序难以理解和难以修改。任何使用 goto 语句的程序可以改写成不需要使用 goto 语句的写法。
goto label;
..
.
label: statement;
在这里,label 是识别被标记语句的标识符,可以是任何除 C++ 关键字以外的纯文本。标记语句可以是任何语句,放置在标识符和冒号(:)后边。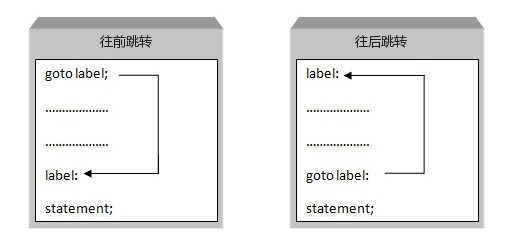
Storage Allocation
- The compiler allocates all the storage for a scope at the opening brace of that scope.
- The constructor call doesn’t happen until the sequence point where the object is defined.
- 编译器为作用域的开大括号分配所有存储空间。
- 构造函数调用直到定义对象的序列点才发生。
```C++
class X {
public:
X();
};
X::X() {}
void f(int i) {
if(i < 10) {
//goto jump1; // Error: goto bypasses init
}
X x1; // Constructor called here
jump1:
switch(i) {
case 1 :
X x2; // Constructor called here
break;
//case 2 : // Error: case bypasses init
X x3; // Constructor called here
break;
}
}
int main() {
f(9);
f(11);
}///:~
在上述代码中,无论是接触goto语句的注释还是解除case2语句的注释,程序都无法顺利通过编译,原因是编译器认为程序可能会跳过x1或者x2的初始化,而这是不被允许的。
#### Local Variables
在`C++`中,一般来说有三个地方可以定义变量:
* 在函数或一个代码块内部声明的变量,称为**局部变量**。
* 在函数参数的定义中声明的变量,称为**形式参数**。
* 在所有函数外部声明的变量,称为**全局变量**。
作用域是程序的一个区域,变量的作用域可以分为以下几种:
* 局部作用域:在函数内部声明的变量 **(局部变量)** 具有局部作用域,它们只能在函数内部访问。局部变量在函数每次被调用时被创建,在函数执行完后被销毁。
* 全局作用域:**在**所有**函数和代码块之外**声明的变量具有全局作用域,它们可以被程序中的任何函数访问。全局变量在程序开始时被创建,在程序结束时被销毁。
* 块作用域:在代码块内部声明的变量具有块作用域,它们只能在代码块内部访问。块作用域变量在代码块每次被执行时被创建,在代码块执行完后被销毁。
* 类作用域:在类内部声明的变量具有类作用域,它们可以被类的所有成员函数访问。类作用域变量的生命周期与类的生命周期相同。
**注意** :如果在内部作用域中声明的变量与外部作用域中的变量同名,则**内部作用域中的变量将覆盖外部作用域中的变量**。
##### 局部变量
在函数或一个代码块内部声明的变量,称为局部变量。它们只能被函数内部或者代码块内部的语句使用。下面的实例使用了局部变量:
```C++
#include <iostream>
using namespace std;
int main ()
{
// 局部变量声明
int a, b;
int c;
// 实际初始化
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}
全局变量
在所有函数外部定义的变量(通常是在程序的头部),称为全局变量。全局变量的值在程序的整个生命周期内都是有效的。
全局变量可以被任何函数访问。也就是说,全局变量一旦声明,在整个程序中都是可用的。下面的实例使用了全局变量和局部变量:
#include <iostream>
using namespace std;
// 全局变量声明
int g;
int main ()
{
// 局部变量声明
int a, b;
// 实际初始化
a = 10;
b = 20;
g = a + b;
cout << g;
return 0;
}
作用域覆盖
在程序中,局部变量和全局变量的名称可以相同,但是在函数内,局部变量的值会覆盖全局变量的值。下面是一个实例:
#include <iostream>
using namespace std;
// 全局变量声明
int g = 20;
int main ()
{
// 局部变量声明
int g = 10;
cout << g;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
10
块作用域
块作用域指的是在代码块内部声明的变量:
#include <iostream>
int main() {
int a = 10;
{
int a = 20; // 块作用域变量
std::cout << "块变量: " << a << std::endl;
}
std::cout << "外部变量: " << a << std::endl;
return 0;
}
以上实例中,内部的代码块中声明了一个名为 a 的变量,它与外部作用域中的变量 a 同名。内部作用域中的变量 a 将覆盖外部作用域中的变量 a,在内部作用域中访问 a 时输出的是20,而在外部作用域中访问 a 时输出的是 10。
当上面的代码被编译和执行时,它会产生下列结果:
块变量: 20
外部变量: 10
类作用域
类作用域指的是在类内部声明的变量:
#include <iostream>
class MyClass {
public:
static int class_var; // 类作用域变量
};
int MyClass::class_var = 30;
int main() {
std::cout << "类变量: " << MyClass::class_var << std::endl;
return 0;
}
以上实例中,MyClass 类中声明了一个名为 class_var 的类作用域变量。可以使用类名和作用域解析运算符 :: 来访问这个变量。在main() 函数中访问 class_var 时输出的是30。
类变量: 30
Initialization
Function Overloading
- Same functions with different arguments list.
允许多个函数共有同一个函数名,他们可以有不同的参数。
调用时回自动根据输入的参数匹配要调用的函数。
void print(char * str, int width); // #1
void print(double d, int width); // #2
void print(long l, int width); // #3
void print(int i, int width); // #4
void print(char *str); // #5
print("Pancakes", 15);
print("Syrup");
print(1999.0, 10);
print(1999, 12);
print(1999L, 15);
Overloading Hiding
Week 5
Inline and Inheritance
Inline Function
在 c/c++ 中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了 inline 修饰符,表示为内联函数。
栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。
在系统下,栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足而导致程序出错的问题,如,函数的死循环递归调用的最终结果就是导致栈内存空间枯竭。
下面我们来看一个例子:
#include <stdio.h>
inline const char *num_check(int v)
{
return (v % 2 > 0) ? "奇" : "偶";
}
int main(void)
{
int i;
for (i = 0; i < 100; i++)
printf("%02d %s\n", i, num_check(i));
return 0;
}
上面的例子就是标准的内联函数的用法,使用 inline 修饰带来的好处我们表面看不出来,其实,在内部的工作就是在每个 for 循环的内部任何调用 dbtest(i) 的地方都换成了 (i%2>0)?"奇":"偶",这样就避免了频繁调用函数对栈内存重复开辟所带来的消耗。
内联函数和宏定义很近似,但是本质上还是函数,而不是宏定义那样直接的替换。
#define f(a) (a)+(a)
main(){
double a = 4;
printf(“%d”, f(a));
}
inline int f(int i){
return i*2;
}
main(){
double a = 4;
printf(“%d”, f(a));
}
如上面的inline和宏是不同的。
inline使用限制
inline 的使用是有所限制的,inline 只适合函数体内代码简单的函数使用,不能包含复杂的结构控制语句例如 while、switch,并且不能内联函数本身不能是直接递归函数(即,自己内部还调用自己的函数)。
inline仅是一个对编译器的建议
inline 函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
inline函数的定义放在头文件中
其次,因为内联函数要在调用点展开,所以编译器必须随处可见内联函数的定义,要不然就成了非内联函数的调用了。所以,这要求每个调用了内联函数的文件都出现了该内联函数的定义。
因此,将内联函数的定义放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。
声明跟定义要一致:如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为。如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
Inheritance
Introduction
面向对象程序设计中最重要的一个概念是继承。继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。这样做,也达到了重用代码功能和提高执行效率的效果。
当创建一个类时,您不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。
继承代表了 is-a 关系。例如,哺乳动物是动物,狗是哺乳动物,因此,狗是动物,等等。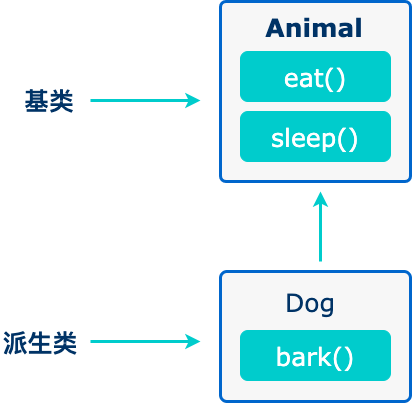
基类 & 派生类
一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表来指定基类。类派生列表以一个或多个基类命名,形式如下:
class derived-class: access-specifier base-class
其中,访问修饰符access-specifier是public、protected或private其中的一个,base-class是之前定义过的某个类的名称。如果未使用访问修饰符 access-specifier,则默认为private。
派生类可以访问基类中所有的非私有成员。因此基类成员如果不想被派生类的成员函数访问,则应在基类中声明为 private。
我们可以根据访问权限总结出不同的访问类型,如下所示:
| 访问 | public | protected | private |
|---|---|---|---|
| 同一个类 | yes | yes | yes |
| 派生类 | yes | yes | no |
| 外部的类 | yes | no | no |
一个派生类继承了所有的基类方法,但下列情况除外:
- 基类的构造函数、析构函数和拷贝构造函数。
- 基类的重载运算符。
- 基类的友元函数。
友元函数
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元。
如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend,如下所示:
class Box
{
double width;
public:
double length;
friend void printWidth( Box box );
void setWidth( double wid );
};
声明类 ClassTwo 的所有成员函数作为类 ClassOne 的友元,需要在类 ClassOne 的定义中放置如下声明:
friend class ClassTwo;
请看下面的程序:
#include <iostream>
using namespace std;
class Box
{
double width;
public:
friend void printWidth( Box box );
void setWidth( double wid );
};
// 成员函数定义
void Box::setWidth( double wid )
{
width = wid;
}
// 请注意:printWidth() 不是任何类的成员函数
void printWidth( Box box )
{
/* 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员 */
cout << "Width of box : " << box.width <<endl;
}
// 程序的主函数
int main( )
{
Box box;
// 使用成员函数设置宽度
box.setWidth(10.0);
// 使用友元函数输出宽度
printWidth( box );
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Width of box : 10
示例代码
#include <iostream>
using namespace std;
// 基类
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 派生类
class Rectangle: public Shape
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// 输出对象的面积
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Total area: 35
继承类型
当一个类派生自基类,该基类可以被继承为 public、protected 或 private 几种类型。继承类型是通过上面讲解的访问修饰符 access-specifier 来指定的。
我们几乎不使用 protected 或 private 继承,通常使用 public 继承。当使用不同类型的继承时,遵循以下几个规则:
- 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基类的公有和保护成员来访问。
- 保护继承(protected): 当一个类派生自保护基类时,基类的公有和保护成员将成为派生类的保护成员。
- 私有继承(private):当一个类派生自私有基类时,基类的公有和保护成员将成为派生类的私有成员。
多重继承
多重继承即一个子类可以有多个父类,它继承了多个父类的特性。
C++ 类可以从多个类继承成员,语法如下:
class <派生类名>:<继承方式1><基类名1>,<继承方式2><基类名2>,…
{
<派生类类体>
};
其中,访问修饰符继承方式是 public、protected 或 private 其中的一个,用来修饰每个基类,各个基类之间用逗号分隔,如上所示。现在让我们一起看看下面的实例:
#include <iostream>
using namespace std;
// 基类 Shape
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 基类 PaintCost
class PaintCost
{
public:
int getCost(int area)
{
return area * 70;
}
};
// 派生类
class Rectangle: public Shape, public PaintCost
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// 输出对象的面积
cout << "Total area: " << Rect.getArea() << endl;
// 输出总花费
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Total area: 35
Total paint cost: $2450
派生类在继承基类的成员变量时,会单独开辟一块内存保存基类的成员变量,因此派生类自己的成员变量即使和基类的成员变量重名,但是也不会引起冲突。如下代码:
#include <iostream>
using namespace std;
//基类
class A
{
public:
A(){n = 0;};
~A(){};
int getA(){ return n;};
void setA(int t){ n = t;};
private:
int n;
};
//派生类
class B :public A
{
public:
B(){ n = 0;};
~B(){};
int getB(){ return n;};
void setB(int t){ n = t;};
private:
int n;
};
int main(int argc, char * argv[])
{
B b;
b.setA(10); //设置基类的成员变量n
cout<<"A::n "<<b.getA()<<endl;
cout<<"B::n "<<b.getB()<<endl;
b.setB(9); //设置派生类的成员变量n
cout<<"A::n "<<b.getA()<<endl;
cout<<"B::n "<<b.getB()<<endl;
return 0;
}
结果如下:
A::n 10
B::n 0
A::n 10
B::n 9
继承顺序
构造函数调用顺序:基类 > 成员类 > 派生类;
多继承派生类: 基类构造顺序 依照 基类继承顺序调用
类成员:依照 类成员对象 定义顺序 调用成员类构造函数
#include <iostream>
using namespace std;
class Shape { // 基类 Shape
public:
Shape() {
cout << "Shape" << endl;
}
~Shape() {
cout << "~Shape" << endl;
}
};
class PaintCost { // 基类 PaintCost
public:
PaintCost() {
cout << "PaintCost" << endl;
}
~PaintCost() {
cout << "~PaintCost" << endl;
}
};
// 派生类
class Rectangle : public Shape, public PaintCost //基类构造顺序 依照 继承顺序
{
public:
Rectangle() :b(), a(), Shape(), PaintCost(){
cout << "Rectangle" << endl;
}
~Rectangle() {
cout << "~Rectangle" << endl;
}
PaintCost b; // 类成员变量构造顺序 依照 变量定义顺序
Shape a;
};
int main(void)
{
Rectangle Rect;
return 0;
}
结果:
Shape
PaintCost
PaintCost
Shape
Rectangle
~Rectangle
~Shape
~PaintCost
~PaintCost
~Shape
Composition
组合:一个类包含另一个类对象
- 继承是一种is-a的关系。也就是说每个子类对象都是一个基类对象;
- 组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象(一个对象里套了另外一个对象)
应用场景
- 如果只单纯考虑代码的复用,优先考虑组合;
- 继承体系下,父类和子类耦合性太高,父类中某一成员更改,各子类中所继承的成员都要改
示例代码
#include <iostream>
#include <string>
using namespace std;
class Rooms
{
public:
Rooms(string name);
void set_doors(int up, int down, int west, int east);//-1 means no exit, 0 means exit to the first room, 1 means exit to the second room, and so on.
void set_monster();//set the monster
void set_princess();//set the princess
void set_Excalibur();//set the Excalibur
void moster_die();//kill the monster
void princess_leave();//the princess leave
void Excalibur_leave();//the Excalibur leave
string get_name();//return the name of the room
void get_exits(vector<int> &exit);//return the exits of the room
int get_next_room(int direction);//return the next room number
int check_the_info();//check the info of the room
private:
bool Excalibur;
bool monster;
bool princess;
string name;
int way_to_up, way_to_down, way_to_east, way_to_west;
};
class adventure {
public:
adventure();
void generate_map();
void show_info();
void command();
void go_to_next_room(int direction);
int Encounter();
private:
int current_room;
vector<Rooms*> rooms;//这里就是组合的体现
bool princess_status;
bool Excalibur_status;
};
Conversions
转换:当一个对象被用作另一个类型的对象时,编译器会自动将其转换为另一个类型。C++允许我们将一种类型的数据转换为另一种类型的数据。这称为类型转换。C++中有两种类型的类型转换。
- 隐式转换
- 显式转换(也称为强制类型转换)
Implicit Conversions
隐式转换:当一个对象被用作另一个类型的对象时,编译器会自动将其转换为另一个类型。示例代码
结果:#include <iostream> using namespace std; int main() { int num_int; // 声明一个double变量 double num_double=9.99; // 隐式转换 // 将double值分配给int变量 num_int = num_double; cout << "num_int = " << num_int << endl; cout << "num_double = " << num_double << endl; return 0; }
在程序中,我们已将int数据分配给double变量。num_int = 9 num_double = 9.99
此处,在将num_int = num_double;double值分配给num_int变量之前,它会由编译器自动转换为int。 这是隐式类型转换的示例。
Explicit Conversions
显式转换:当一个对象被用作另一个类型的对象时,编译器不会自动将其转换为另一个类型,需要使用强制类型转换。
示例代码
#include <iostream>
using namespace std;
int main() {
// 初始化double变量
double num_double = 3.56;
cout << "num_double = " << num_double << endl;
// 从double到int的C风格转换
int num_int1 = (int)num_double;
cout << "num_int1 = " << num_int1 << endl;
// 从double到int的函数样式转换
int num_int2 = int(num_double);
cout << "num_int2 = " << num_int2 << endl;
return 0;
}
结果:
num_double = 3.56
num_int1 = 3
num_int2 = 3
我们使用C风格类型转换和函数样式转换进行类型转换,并显示结果。由于它们执行相同的任务,因此两者都给我们相同的输出。
拷贝构造函数
拷贝构造函数是一种特殊的构造函数,它在创建对象时,是使用同一类中之前创建的对象来初始化新创建的对象。拷贝构造函数通常用于:
- 通过使用另一个同类型的对象来初始化新创建的对象。
- 复制对象把它作为参数传递给函数。
- 复制对象,并从函数返回这个对象。
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。拷贝构造函数的最常见形式如下:
在这里,classname (const classname &obj) { // 构造函数的主体 }obj是一个对象引用,该对象是用于初始化另一个对象的。
示例代码
#include <iostream>
using namespace std;
class Line
{
public:
// 定义构造函数
Line( double len ); // 简单的构造函数
Line( const Line &obj); // 拷贝构造函数
~Line(); // 析构函数
double getLength( void );
void setLength( double len );
Line operator+(const Line& line);
private:
double length;
};
// 成员函数定义,包括构造函数
Line::Line(double len)
{
cout << "Object is being created, length = " << len << endl;
length = len;
}//构造函数
Line::Line(const Line &obj)
{
cout << "Object is being created(copied), length = " << obj.length << endl;
length = obj.length;
}//拷贝构造函数
Line::~Line(void)
{
cout << "Object is being deleted" << endl;
}//析构函数
double Line::getLength(void)
{
return length;
}
void Line::setLength(double len)
{
length = len;
}
void display(Line obj)
{
cout << "line is : " << obj.getLength() <<endl;
}
Line Line::operator+(const Line& line)
{
return Line(length + line.length);//这里会调用拷贝构造函数
}//操作符重载
int main( )
{
Line line1(10.0);
Line line2 = line1; // 这里会调用拷贝构造函数,通过使用另一个同类型的对象来初始化新创建的对象
Line line3 = line1 + line2; // 这里会调用拷贝构造函数,复制对象把它作为参数传递给函数
display(line3); // 这里会调用拷贝构造函数,复制对象把它作为参数传递给函数
return 0;
}
结果:
Object is being created, length = 10
Object is being created(copied), length = 10
Object is being created(copied), length = 20
Object is being created(copied), length = 20
line is : 20
Object is being deleted
Object is being deleted
Object is being deleted
Object is being deleted
Week 6
Polymorphism
多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。C++多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数.
What is Polymorphism?
下面的实例中,基类 Shape 被派生为两个类,如下所示:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// 程序的主函数
int main( )
{
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// 存储矩形的地址
shape = &rec;
// 调用矩形的求面积函数 area
shape->area();
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area();
return 0;
}
结果:
Rectangle class area :
Triangle class area :
导致错误输出的原因是,调用函数 area() 被编译器设置为基类中的版本,这就是所谓的静态多态,或静态链接——函数调用在程序执行前就准备好了。有时候这也被称为早绑定,因为 area() 函数在程序编译期间就已经设置好了。
但现在,让我们对程序稍作修改,在 Shape 类中,area() 的声明前放置关键字 virtual,如下所示:
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
修改后,当编译和执行前面的实例代码时,它会产生以下结果:
Rectangle class area :
Triangle class area :
此时,编译器看的是指针的内容,而不是它的类型。因此,由于 tri 和 rec 类的对象的地址存储在 *shape 中,所以会调用各自的 area()函数。
正如您所看到的,每个子类都有一个函数area() 的独立实现。这就是多态的一般使用方式。有了多态,您可以有多个不同的类,都带有同一个名称但具有不同实现的函数,函数的参数甚至可以是相同的。
Virtual Functions
虚函数是在基类中使用 virtual 关键字声明的函数。在派生类中重新定义基类的虚函数时,会告诉编译器不要静态链接该函数,而是在运行时根据所使用的对象类型来动态链接该函数。
您可能想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是您在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数。
我们可以把基类中的虚函数 area() 改写如下:
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};
= 0 告诉编译器,函数没有主体,上面的虚函数是纯虚函数。
Overriding
派生类可以重新定义基类的虚函数。这种行为称为覆盖,也称为重写或重新定义。
在派生类中,覆盖基类中的虚函数时,必须使用相同的函数签名。也就是说,覆盖函数的参数必须与基类中的虚函数的参数完全相同。如果要覆盖基类中的虚函数,必须在派生类中使用相同的函数名称和参数列表。
下面的实例中,我们重新定义了基类中的 area() 函数,如下所示:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// 程序的主函数
int main( )
{
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// 存储矩形的地址
shape = &rec;
// 调用矩形的求面积函数 area
shape->area();
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area();
return 0;
}
结果:
Rectangle class area :
Triangle class area :
C++11 中的 override 关键字
override 关键字是 C++11 引入的,它可以让编译器检查派生类中的函数是否覆盖了基类中的虚函数。如果派生类中的函数没有覆盖基类中的虚函数,编译器会报错。
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area () override
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area () override
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
如果我们在派生类中定义了一个希望覆写基类中虚函数但是签名不一致(如参数列表不一样、函数名打错)使用 override 关键字的函数,编译器会报错:
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area (int x) override
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
error: 'int Rectangle::area()' marked 'override', but does not override
C++11 中的 final 关键字
禁用继承
C++11中允许将类标记为final,方法时直接在类名称后面使用关键字final,如此,意味着继承该类会导致编译错误。
class Super final
{
//......
};
禁用虚函数的override
C++11中允许将虚函数标记为final,方法是在虚函数声明后面使用关键字final,如此,意味着继承该类的子类不能覆盖该虚函数,否则会导致编译错误。
class Base
{
public:
virtual void foo() final;
};
class Derived : public Base
{
public:
virtual void foo(); // 编译错误
};
关于C++虚表和动态链接的详细介绍可以参考:C++虚表
Week 7
C++模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。
每个容器都有一个单一的定义,比如向量,我们可以定义许多不同类型的向量,比如 vector <int> 或 vector <string>。
您可以使用模板来定义函数和类,接下来让我们一起来看看如何使用。
函数模板
模板函数定义的一般形式如下所示:
template <typename type> ret-type func-name(parameter list)
{
// 函数的主体
}
在这里,type 是函数所使用的数据类型的占位符名称。这个名称可以在函数定义中使用。
下面是函数模板的实例,返回两个数中的最大值:
#include <iostream>
#include <string>
using namespace std;
template <typename T>
inline T const& Max (T const& a, T const& b)
{
return a < b ? b:a;
}
int main ()
{
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): World
类模板
正如我们定义函数模板一样,我们也可以定义类模板。泛型类声明的一般形式如下所示:
template <class type> class class-name {
.
.
.
}
在这里,type 是占位符类型名称,可以在类被实例化的时候进行指定。您可以使用一个逗号分隔的列表来定义多个泛型数据类型。
下面的实例定义了类 Stack<>,并实现了泛型方法来对元素进行入栈出栈操作:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T> class Stack {
private:
vector<T> elems; // 元素
public:
void push(T const&); // 入栈
void pop(); // 出栈
T top() const; // 返回栈顶元素
bool empty() const{ // 如果为空则返回真。
return elems.empty();
}
};
template <class T>void Stack<T>::push (T const& elem)
{
// 追加传入元素的副本
elems.push_back(elem);
}
template <class T>void Stack<T>::pop ()
{
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// 删除最后一个元素
elems.pop_back();
}
template <class T>T Stack<T>::top () const
{
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// 返回最后一个元素的副本
return elems.back();
}
int main()
{
try {
Stack<int> intStack; // int 类型的栈
Stack<string> stringStack; // string 类型的栈
// 操作 int 类型的栈
intStack.push(7);
cout << intStack.top() <<endl;
// 操作 string 类型的栈
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
}
catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}
当上面的代码被编译和执行时,它会产生下列结果:
7
hello
Exception: Stack<>::pop(): empty stack
Template Specialization
模板特化允许用户为特定的类型参数指定模板,这样就可以使用一个常规的模板来处理大部分的情况,而有时对于特定的类型,您可能希望有一个特殊的版本,这个特殊的版本可以提供更为有效的处理。
具体可以参考这里:C++ 模板特化
STL lib
C++ STL(标准模板库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法和数据结构,如向量、链表、队列、栈。
C++ 标准模板库的核心包括以下三个组件:
| 组件 | 描述 |
|---|---|
容器(Containers) |
容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。 |
算法(Algorithms) |
算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。 |
迭代器(iterators) |
迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。 |
这三个组件都带有丰富的预定义函数,帮助我们通过简单的方式处理复杂的任务。
Containers
容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。
- 序列式容器(Sequence containers),每个元素都有固定位置--取决于插入时机和地点,和元素值无关,
vector、deque、list;Vector:将元素置于一个动态数组中加以管理,可以随机存取元素(用索引直接存取),数组尾部添加或移除元素非常快速。但是在中部或头部安插元素比较费时;Deque:是“double-ended queue”的缩写,可以随机存取元素(用索引直接存取),数组头部和尾部添加或移除元素都非常快速。但是在中部或头部安插元素比较费时;List:双向链表,不提供随机存取(按顺序走到需存取的元素,$O(n)$),在任何位置上执行插入或删除动作都非常迅速,内部只需调整一下指针;
关联式容器(Associative containers),元素位置取决于其值,
set、multiset、map、multimap;Set&Multiset:内部的元素依据其值自动排序,Set内的相同数值的元素只能出现一次,Multisets内可包含多个数值相同的元素,内部由二叉树实现,便于查找;Map&Multimap:Map的元素是成对的键值/实值,内部的元素依据其值自动排序,Map内的相同数值的元素只能出现一次,Multimaps内可包含多个数值相同的元素,内部由二叉树实现,便于查找;
容器适配器(Container adaptors),提供一种不同的接口,
stack、queue、priority_queue;Stack:栈,先进后出(FILO),内部以deque实现;Queue:队列,先进先出(FIFO),内部以deque实现;Priority_queue:优先队列,内部以vector实现,元素以优先级排序,最高优先级的元素总是位于队列头部,可以随机存取元素(用索引直接存取);
容器类自动申请和释放内存,无需new和delete操作。
Algorithms
函数库对数据类型的选择对其可重用性起着至关重要的作用。举例来说,一个求方根的函数,在使用浮点数作为其参数类型的情况下的可重用性肯定比使用整型作为它的参数类性要高。而C++通过模板的机制允许推迟对某些类型的选择,直到真正想使用模板或者说对模板进行特化的时候,STL就利用了这一点提供了相当多的有用算法。它是在一个有效的框架中完成这些算法的——你可以将所有的类型划分为少数的几类,然后就可以在模版的参数中使用一种类型替换掉同一种类中的其他类型。STL提供了大约100个实现算法的模版函数,比如算法for_each将为指定序列中的每一个元素调用指定的函数,stable_sort以你所指定的规则对序列进行稳定性排序等等。只要我们熟悉了STL之后,许多代码可以被大大的化简,只需要通过调用一两个算法模板,就可以完成所需要的功能并大大地提升效率。
算法部分主要由头文件<algorithm>,<numeric>和<functional>组成。<algorithm>是所有STL头文件中最大的一个(尽管它很好理解),它是由一大堆模版函数组成的,可以认为每个函数在很大程度上都是独立的,其中常用到的功能范围涉及到比较、交换、查找、遍历操作、复制、修改、移除、反转、排序、合并等等。<numeric>体积很小,只包括几个在序列上面进行简单数学运算的模板函数,包括加法和乘法在序列上的一些操作。<functional>中则定义了一些模板类,用以声明函数对象。
STL中算法大致分为四类:
- 非可变序列算法:指不直接修改其所操作的容器内容的算法。
- 可变序列算法:指可以修改它们所操作的容器内容的算法。
- 排序算法:对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
- 数值算法:对容器内容进行数值计算。
Iterators
Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。或者这样说可能更容易理解:Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
迭代器的作用:能够让迭代器与算法不干扰的相互发展,最后又能无间隙的粘合起来,重载了*,++,==,!=,=运算符。用以操作复杂的数据结构,容器提供迭代器,算法使用迭代器;常见的一些迭代器类型:iterator、const_iterator、reverse_iterator和const_reverse_iterator.
Widely Used Containers & Containers Adaptors
vector
Ctors
vector():创建一个空vectorvector(int nSize):创建一个vector,元素个数为nSizevector(int nSize,const t& t):创建一个vector,元素个数为nSize,且值均为tvector(const vector&):拷贝构造函数vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中
增加函数
void push_back(const T& x):向量尾部增加一个元素Xiterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一个元素xiterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n个相同的元素xiterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
删除函数
iterator erase(iterator it):删除向量中迭代器指向元素iterator erase(iterator first,iterator last):删除向量中[first,last)中元素void pop_back():删除向量中最后一个元素void clear():清空向量中所有元素
遍历函数
reference at(int pos):返回pos位置元素的引用reference front():返回首元素的引用reference back():返回尾元素的引用iterator begin():返回向量头指针,指向第一个元素iterator end():返回向量尾指针,指向向量最后一个元素的下一个位置reverse_iterator rbegin():反向迭代器,指向最后一个元素reverse_iterator rend():反向迭代器,指向第一个元素之前的位置
判断函数
bool empty() const:判断向量是否为空,若为空,则向量中无元素
大小函数
int size() const:返回向量中元素的个数int capacity() const:返回当前向量所能容纳的最大元素值int max_size() const:返回最大可允许的vector元素数量值
其他函数
void swap(vector&):交换两个同类型向量的数据void assign(int n,const T& x):设置向量中第n个元素的值为xvoid assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素
Example
vector的初始化
#include <iostream>
#include <vector>
using namespace std;
vector<int> v1;
vector<int> v2(10);
vector<int> v3(10,1);
vector<int> v4(v3);
vector<int> v5(v3.begin(),v3.end());
vector的遍历
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for(vector<int>::iterator it=v.begin();it!=v.end();it++)//迭代器遍历
{
cout<<*it<<endl;
}
for(int i=0;i<obj.size();i++)//下标遍历,不建议使用
{
cout<<obj[i]<<",";
return 0;
}
vector的排序
#include <iostream>
#include <vector>
#include <algorithm>//sort函数头文件
using namespace std;
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
sort(v.begin(),v.end());//从小到大排序
for(vector<int>::iterator it=v.begin();it!=v.end();it++)
{
cout<<*it<<endl;
}
reverse(v.begin(),v.end());//从大到小排序
for(vector<int>::iterator it=v.begin();it!=v.end();it++)
{
cout<<*it<<endl;
}
return 0;
}
vector定义二维数组
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int N=5, M=6;
vector<vector<int> > obj(N); //定义二维动态数组大小5行
for(int i =0; i< obj.size(); i++)//动态二维数组为5行6列,值全为0
{
obj[i].resize(M);
}
//或者
vector<vector<int> > obj(N, vector<int>(M)); //定义二维动态数组5行6列
return 0;
}
list
list的初始化
#include<list> // 头文件
list<type> li; // 声明一个元素类型为type的双向链表li
list<type> li(size); // 声明一个类型为type、含有size个默认值初始化元素的的双向链表li
list<type> li(size, value); // 声明一个元素类型为type、含有size个value元素的双向链表li
list<type> li(mylist); // li是mylist的一个副本
list<type> li(first, last); // 使用迭代器first、last范围内的元素初始化li
list的常用操作
#include<list>
list<type> li;
li[ ]//返回li中第i个元素的引用
li.front()//返回li中第一个元素的引用
li.back()//返回li中最后一个元素的引用
li.begin()//返回指向li中第一个元素的迭代器
li.end()//返回指向li中最后一个元素的下一个位置的迭代器
li.rbegin()//返回指向li中最后一个元素的反向迭代器
li.rend()//返回指向li中第一个元素的反向迭代器
li.empty()//判断li是否为空,若为空,则li中无元素
li.size()//返回li中元素的个数
li.max_size()//返回li中最大可允许的元素个数
li.clear()//清空li中的元素
li.insert(it, value)//在迭代器it指向的元素之前插入值为value的元素
li.insert(it, n, value)//在迭代器it指向的元素之前插入n个值为value的元素
li.insert(it, first, last)//在迭代器it指向的元素之前插入迭代器first和last之间的所有元素
li.erase(it)//删除迭代器it指向的元素
li.erase(first, last)//删除迭代器first和last之间的所有元素
li.push_back(value)//在li的末尾添加值为value的元素
li.pop_back()//删除li末尾的元素
li.push_front(value)//在li的头部添加值为value的元素
li.pop_front()//删除li头部的元素
li.resize(num)//将li中元素的个数调整为num个,若num小于li中元素的个数,则删除多余的元素;
li.reverse()//将li中的元素逆置
li.sort()//将li中的元素按升序排列
li.unique()//删除li中所有重复的元素
li.merge(li2)//将li2中的元素合并到li中,li2中的元素也会被删除
li.splice(it, li2)//将li2中的元素插入到迭代器it指向的元素之前,li2中的元素也会被删除
li.splice(it, li2, first, last)//将li2中迭代器first和last之间的所有元素插入到迭代器it指向的元素之前,li2中的元素也会被删除
li.assign(first, last)//将迭代器first和last之间的所有元素赋值给li
li.assign(n, value)//将n个值为value的元素赋值给li
li.swap(li2)//将li和li2中的元素进行交换
li.accumulate(first, last, value)//计算迭代器first和last之间的所有元素的和,value为初始值
li.remove(value)//删除li中所有值为value的元素
li.remove_if(pred)//删除li中所有满足谓词pred的元素
map/multimap
map和multimap都需要#include<map>,唯一的不同是,map的键值key不可重复,而multimap可以,也正是由于这种区别,map支持[ ]运算符,multimap不支持[ ]运算符。在用法上没什么区别。
C++中map提供的是一种键值对容器,里面的数据都是成对出现的,如下图:每一对中的第一个值称之为关键字(key),每个关键字只能在map中出现一次;第二个称之为该关键字的对应值。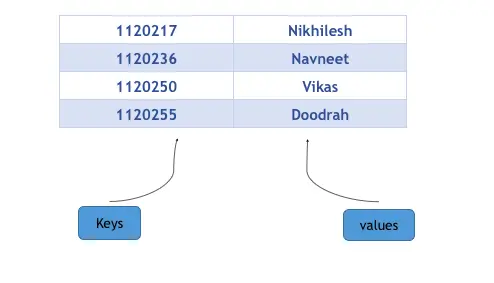
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。这里说下map内部数据的组织,map内部自建一颗红黑树,这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。
map的初始化
#include<map> // 头文件
map<type1, type2> mp; // 声明一个键值类型分别为type2->type1的map
map<type1, type2> mp(mymp); // mp是mymp的一个副本
map<type1, type2> mp(first, last); // 使用迭代器first、last范围内的元素初始化mp
map的常用操作
#include<map>
map<type1, type2> mp;
mp[ ]//返回键值为key的元素的引用
mp.at(key)//返回键值为key的元素的引用
mp.begin()//返回指向map中第一个元素的迭代器
mp.end()//返回指向map中最后一个元素的下一个位置的迭代器
mp.rbegin()//返回指向map中最后一个元素的反向迭代器
mp.rend()//返回指向map中第一个元素的前一个位置的反向迭代器
mp.clear()//清空mp中的元素
mp.count(key)//返回键值等于key的元素的个数
mp.empty()//判断mp是否为空
mp.erase(it)//删除迭代器it指向的元素
mp.erase(first, last)//删除迭代器first和last之间的所有元素
mp.find(key)//返回一个迭代器,指向键值为key的元素,如果没找到则返回end()
mp.insert(map<int, string>::value_type (elem1, elem2))//在mp中插入(elem1,ekem2)返回一个pair,其第一个元素为一个迭代器,指向键值为elem.first的元素,第二个元素为一个bool值,表示插入是否成功
mp.insert(first, last)//在mp中插入迭代器first和last之间的所有元素
mp.lower_bound(key)//返回一个迭代器,指向键值>=key的第一个元素
mp.upper_bound(key)//返回一个迭代器,指向键值>key的第一个元素
mp.size()//返回mp中元素的个数
mp.swap(mp2)//交换mp和mp2中的元素
map的遍历
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<int, string> mapStudent;
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
mapStudent.insert(map<int, string>::value_type (2, "student_two"));
mapStudent.insert(map<int, string>::value_type (3, "student_three"));
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<<iter->first<<' '<<iter->second<<endl;
}
set/multiset
std::set是关联容器,含有Key类型对象的已排序集。用比较函数compare进行排序。搜索、移除和插入拥有对数复杂度。set通常以红黑树实现。
set容器内的元素会被自动排序,set与map不同,set中的元素即是键值又是实值,set不允许两个元素有相同的键值。不能通过set的迭代器去修改set元素,原因是修改元素会破坏set组织。当对容器中的元素进行插入或者删除时,操作之前的所有迭代器在操作之后依然有效。
由于set元素是排好序的,且默认为升序,因此当set集合中的元素为结构体或自定义类时,该结构体或自定义类必须实现运算符‘<’的重载。
multiset特性及用法和set完全相同,唯一的差别在于它允许键值重复。set和multiset的底层实现是一种高效的平衡二叉树,即红黑树(Red-Black Tree)。set的初始化
#include<set> // 头文件 set<type> st; // 声明一个元素类型为type的集合st set<type> st(myset); // st是myset的一个副本 set<type> st(first, last); // 使用迭代器first、last范围内的元素初始化stset的常用操作
#include<set> set<type> st; st[ ]//返回键值为key的元素的引用 st.at(key)//返回键值为key的元素的引用 st.begin()//返回指向set中第一个元素的迭代器 st.end()//返回指向set中最后一个元素的下一个位置的迭代器 st.rbegin()//返回指向set中最后一个元素的反向迭代器 st.rend()//返回指向set中第一个元素的前一个位置的反向迭代器 st.clear()//清空st中的元素 st.count(key)//返回键值等于key的元素的个数 st.empty()//判断st是否为空 st.erase(it)//删除迭代器it指向的元素 st.erase(first, last)//删除迭代器first和last之间的所有元素 st.find(key)//返回一个迭代器,指向键值为key的元素,如果没找到则返回end() st.insert(elem)//在st中插入elem st.insert(first, last)//在st中插入迭代器first和last之间的所有元素 st.lower_bound(key)//返回一个迭代器,指向键值>=key的第一个元素 st.upper_bound(key)//返回一个迭代器,指向键值>key的第一个元素 st.size()//返回st中元素的个数 st.swap(st2)//交换st和st2中的元素set的遍历
#include <set> #include <string> #include <iostream> using namespace std; int main() { set<int> setStudent; setStudent.insert(1); setStudent.insert(2); setStudent.insert(3); set<int>::iterator iter; for(iter = setStudent.begin(); iter != setStudent.end(); iter++) cout<<*iter<<' '; }
deque
deque的初始化
#include<deque> // 头文件
deque<type> deq; // 声明一个元素类型为type的双端队列que
deque<type> deq(size); // 声明一个类型为type、含有size个默认值初始化元素的的双端队列que
deque<type> deq(size, value); // 声明一个元素类型为type、含有size个value元素的双端队列que
deque<type> deq(mydeque); // deq是mydeque的一个副本
deque<type> deq(first, last); // 使用迭代器first、last范围内的元素初始化deq
deque的常用操作
#include<deque>
deq[ ]//用来访问双向队列中单个的元素。
deq.front()//返回第一个元素的引用。
deq.back()//返回最后一个元素的引用。
deq.push_front(x)//把元素x插入到双向队列的头部。
deq.pop_front()//弹出双向队列的第一个元素。
deq.push_back(x)//把元素x插入到双向队列的尾部。
deq.pop_back()//弹出双向队列的最后一个元素。
deq.begin()//返回指向双向队列开头的迭代器。
deq.end()//返回指向双向队列末尾的迭代器。
deq.rbegin()//返回指向双向队列末尾的逆向迭代器。
deq.rend()//返回指向双向队列开头的逆向迭代器。
deq.clear()//清空双向队列。
deque的排序
#include <iostream>
#include <deque>
#include <algorithm>
using namespace std;
int main()
{
deque<int> deq;
deq.push_back(1);
deq.push_back(2);
deq.push_back(3);
sort(deq.begin(),deq.end());//从小到大排序
for(deque<int>::iterator it=deq.begin();it!=deq.end();it++)
{
cout<<*it<<endl;
}
reverse(deq.begin(),deq.end());//从大到小排序
for(deque<int>::iterator it=deq.begin();it!=deq.end();it++)
{
cout<<*it<<endl;
}
return 0;
}
deque的一些特点
- 支持随机访问,即支持
[ ]以及at(),但是性能没有vector好。 - 可以在内部进行插入和删除操作,但性能不及
list。 deque两端都能够快速插入和删除元素,而vector只能在尾端进行。deque的元素存取和迭代器操作会稍微慢一些,因为deque的内部结构会多一个间接过程。deque迭代器是特殊的智能指针,而不是一般指针,它需要在不同的区块之间跳转。deque可以包含更多的元素,其max_size可能更大,因为不止使用一块内存。deque不支持对容量和内存分配时机的控制。- 在除了首尾两端的其他地方插入和删除元素,都将会导致指向
deque元素的任何pointers、references、iterators失效。不过,deque的内存重分配优于vector,因为其内部结构显示不需要复制所有元素。 deque的内存区块不再被使用时,会被释放,deque的内存大小是可缩减的。不过,是不是这么做以及怎么做由实际操作版本定义。deque不提供容量操作:capacity()和reverse(),但是vector可以。
Container Adapters
stack
stack<int> s;
stack< int, vector<int> > stk; //覆盖基础容器类型,使用vector实现stk
s.empty(); //判断stack是否为空,为空返回true,否则返回false
s.size(); //返回stack中元素的个数
s.pop(); //删除栈顶元素,但不返回其值
s.top(); //返回栈顶元素的值,但不删除此元素
s.push(item); //在栈顶压入新元素item
stack example
#include<iostream>
#include<cstdio>
#include<string>
#include<stack>
using namespace std;
int main()
{
string s;
stack<char> ss;
while (cin >> s)
{
bool flag = true;
for (char c : s) //C++11新标准,即遍历一次字符串s
{
if (c == '(' || c == '{' || c == '[')
{
ss.push(c);
continue;
}
if (c == '}')
{
if (!ss.empty() && ss.top() == '{')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ']')
{
if (ss.top() == '[')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ')')
{
if (ss.top() == '(')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
}
if (flag) cout << "Match!" << endl;
else cout << "Not Match!" << endl;
}
}
queue
queue<int> q; //priority_queue<int> q;
q.empty(); //判断队列是否为空
q.size(); //返回队列长度
q.push(item); //对于queue,在队尾压入一个新元素
//对于priority_queue,在基于优先级的适当位置插入新元素
//queue only:
q.front(); //返回队首元素的值,但不删除该元素
q.back(); //返回队尾元素的值,但不删除该元素
//priority_queue only:
q.top(); //返回具有最高优先级的元素值,但不删除该元素
Week 8
Overloaded Operator
您可以重定义或重载大部分 C++ 内置的运算符。这样,您就能使用自定义类型的运算符。
重载的运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。与其他函数一样,重载运算符有一个返回类型和一个参数列表。
Box operator+(const Box&);
声明加法运算符用于把两个 Box 对象相加,返回最终的 Box 对象。大多数的重载运算符可被定义为普通的非成员函数或者被定义为类成员函数。如果我们定义上面的函数为类的非成员函数,那么我们需要为每次操作传递两个参数,如下所示:
Box operator+(const Box&, const Box&);
重载运算符为什么要重载为成员函数?
重载为成员函数的运算符将其左侧运算对象作为其第一个参数(this),这样,便可以实现连锁操作。例如:
Box Box::operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
二元运算符重载为成员函数
下面的实例使用成员函数演示了运算符重载的概念。在这里,对象作为参数进行传递,对象的属性使用 this 运算符进行访问,如下所示:
#include <iostream>
using namespace std;
class Box
{
public:
double getVolume(void)
{
return length * breadth * height;
}
void setLength( double len )
{
length = len;
}
void setBreadth( double bre )
{
breadth = bre;
}
void setHeight( double hei )
{
height = hei;
}
// 重载 + 运算符,用于把两个 Box 对象相加
Box operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
Box Box2; // 声明 Box2,类型为 Box
Box Box3; // 声明 Box3,类型为 Box
double volume = 0.0; // 把体积存储在该变量中
// Box1 详述
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// Box2 详述
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// Box1 的体积
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// Box2 的体积
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// 把两个对象相加,得到 Box3
Box3 = Box1 + Box2;
// Box3 的体积
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400
可重载/不可重载运算符
下面是可重载的运算符列表:
| 运算符类型 | 运算符 | ||
|---|---|---|---|
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
||
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于),<=(小于等于),>=(大于等于) |
||
| 逻辑运算符 | ` | (逻辑或),&&(逻辑与),!(逻辑非)` | |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
||
| 自增自减运算符 | ++(自增),--(自减) |
||
| 位运算符 | ` | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移)` | |
| 赋值运算符 | `=, +=, -=, *=, /= , % = , &=, | =, ^=, <<=, >>=` | |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
||
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号),[](下标) |
下面是不可重载的运算符:.:成员访问运算符.*, ->*:成员指针访问运算符:::域运算符sizeof:长度运算符?::条件运算符#: 预处理符号
一元运算符重载
一元运算符只对一个操作数进行操作,下面是一元运算符的实例:
- 递增运算符( ++ )和递减运算符( — )
- 一元减运算符,即负号( - )
- 逻辑非运算符( ! )
一元运算符通常出现在它们所操作的对象的左边,比如 !obj、-obj 和 ++obj,但有时它们也可以作为后缀,比如 obj++ 或 obj—。
下面的实例演示了如何重载一元减运算符( - )。
#include <iostream>
using namespace std;
class Distance
{
private:
int feet; // 0 到无穷
int inches; // 0 到 12
public:
// 所需的构造函数
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i){
feet = f;
inches = i;
}
// 显示距离的方法
void displayDistance()
{
cout << "F: " << feet << " I:" << inches <<endl;
}
// 重载负运算符( - )
Distance operator- ()
{
feet = -feet;
inches = -inches;
return Distance(feet, inches);
}
};
int main()
{
Distance D1(11, 10), D2(-5, 11);
-D1; // 取相反数
D1.displayDistance(); // 距离 D1
-D2; // 取相反数
D2.displayDistance(); // 距离 D2
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
F: -11 I:-10
F: 5 I:-11
前缀和后缀运算符
重载单目运算符++(或 --)作为前缀和后缀:
前缀与后缀重载的语法格式是不同的。int参数仅仅为了区别前++和后++,虽然返回类型不相同,但是返回类型并不作为函数的签名,因此必须使用参数加以区别。
#include <iostream>
using namespace std;
class Complex {
private:
double i;
double j;
public:
Complex(int = 0, int = 0);
void display();
Complex operator ++();//前缀自增
Complex operator ++(int);//后缀自增,参数需要加int
};
Complex::Complex(int a, int b) {
i = a;
j = b;
}
void Complex::display() {
cout << i << '+' << j << 'i' << endl;
}
Complex Complex::operator ++() {
++i;
++j;
return *this;
}
Complex Complex::operator ++(int) {
Complex temp =*this;
++*this;
return temp;
}
int main()
{
Complex comnum1(2,2), comnum2,comnum3;
cout << "自增计算前:" << endl;
cout << "comnum1:";
comnum1.display();
cout << "comnum2:";
comnum2.display();
cout << "comnum3:";
comnum3.display();
cout << endl;
cout << "前缀自增计算后:" << endl;
comnum2 = ++comnum1;
cout << "comnum1:";
comnum1.display();
cout << "comnum2:";
comnum2.display();
cout << endl;
cout << "后缀自增计算后:" << endl;
comnum3 = comnum1++;
cout << "comnum1:";
comnum1.display();
cout << "comnum3:";
comnum3.display();
return 0;
}
输出结果为:
自增计算前:
comnum1:2+2i
comnum2:0+0i
comnum3:0+0i
前缀自增计算后:
comnum1:3+3i
comnum2:3+3i
后缀自增计算后:
comnum1:4+4i
comnum3:3+3i
关系运算符重载
C++ 语言支持各种关系运算符( < 、 > 、 <= 、 >= 、 == 等等),它们可用于比较 C++ 内置的数据类型。
您可以重载任何一个关系运算符,重载后的关系运算符可用于比较类的对象。
下面的实例演示了如何重载 < 运算符,类似地,您也可以尝试重载其他的关系运算符。
#include <iostream>
using namespace std;
class Distance
{
private:
int feet; // 0 到无穷
int inches; // 0 到 12
public:
// 所需的构造函数
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i){
feet = f;
inches = i;
}
// 显示距离的方法
void displayDistance()
{
cout << "F: " << feet << " I:" << inches <<endl;
}
// 重载负运算符( - )
Distance operator- ()
{
feet = -feet;
inches = -inches;
return Distance(feet, inches);
}
// 重载小于运算符( < )
bool operator <(const Distance& d)
{
if(feet < d.feet)
{
return true;
}
if(feet == d.feet && inches < d.inches)
{
return true;
}
return false;
}
};
int main()
{
Distance D1(11, 10), D2(5, 11);
if( D1 < D2 )
{
cout << "D1 is less than D2 " << endl;
}
else
{
cout << "D2 is less than D1 " << endl;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
D2 is less than D1
输入/输出运算符重载
C++ 能够使用流提取运算符 >> 和流插入运算符 << 来输入和输出内置的数据类型。您可以重载流提取运算符和流插入运算符来操作对象等用户自定义的数据类型。
在这里,有一点很重要,我们需要把运算符重载函数声明为类的友元函数,这样我们就能不用创建对象而直接调用函数。
下面的实例演示了如何重载提取运算符 >> 和插入运算符 <<。
#include <iostream>
using namespace std;
class Distance
{
private:
int feet; // 0 到无穷
int inches; // 0 到 12
public:
// 所需的构造函数
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i){
feet = f;
inches = i;
}
friend ostream &operator<<( ostream &output,
const Distance &D )
{
output << "F : " << D.feet << " I : " << D.inches;
return output;
}
friend istream &operator>>( istream &input, Distance &D )
{
input >> D.feet >> D.inches;
return input;
}
};
int main()
{
Distance D1(11, 10), D2(5, 11), D3;
cout << "Enter the value of object : " << endl;
cin >> D3;
cout << "First Distance : " << D1 << endl;
cout << "Second Distance :" << D2 << endl;
cout << "Third Distance :" << D3 << endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
$./a.out
Enter the value of object :
70
10
First Distance : F : 11 I : 10
Second Distance :F : 5 I : 11
Third Distance :F : 70 I : 10
函数调用运算符()重载
函数调用运算符 () 可以被重载,用于设计类似于函数调用的行为。重载 () 时,您不是创造了一种新的调用函数的方式,相反地,这是创建一个可以传递任意数目参数的运算符函数。
#include <iostream>
using namespace std;
class Distance
{
private:
int feet; // 0 到无穷
int inches; // 0 到 12
public:
// 所需的构造函数
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i){
feet = f;
inches = i;
}
// 重载函数调用运算符
Distance operator()(int a, int b, int c)
{
Distance D;
// 进行随机计算
D.feet = a + c + 10;
D.inches = b + c + 100 ;
return D;
}
// 显示距离的方法
void displayDistance()
{
cout << "F: " << feet << " I:" << inches << endl;
}
};
int main()
{
Distance D1(11, 10), D2;
cout << "First Distance : ";
D1.displayDistance();
D2 = D1(10, 10, 10); // invoke operator()
cout << "Second Distance :";
D2.displayDistance();
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
First Distance : F: 11 I:10
Second Distance :F: 30 I:120
赋值运算符重载
就像其他运算符一样,您可以重载赋值运算符=,用于创建一个对象,比如拷贝构造函数。
#include <iostream>
using namespace std;
class Distance
{
private:
int feet; // 0 到无穷
int inches; // 0 到 12
public:
// 所需的构造函数
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i){
feet = f;
inches = i;
}
void operator=(const Distance &D )
{
feet = D.feet;
inches = D.inches;
}
// 显示距离的方法
void displayDistance()
{
cout << "F: " << feet << " I:" << inches << endl;
}
};
int main()
{
Distance D1(11, 10), D2(5, 11);
cout << "First Distance : ";
D1.displayDistance();
cout << "Second Distance :";
D2.displayDistance();
// 使用赋值运算符
D1 = D2;
cout << "First Distance :";
D1.displayDistance();
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
First Distance : F: 11 I:10
Second Distance :F: 5 I:11
First Distance :F: 5 I:11
下标运算符[]重载
下标操作符 [] 通常用于访问数组元素。重载该运算符用于增强操作 C++ 数组的功能。
#include <iostream>
using namespace std;
const int SIZE = 10;
class safearay
{
private:
int arr[SIZE];
public:
safearay()
{
register int i;
for(i = 0; i < SIZE; i++)
{
arr[i] = i;
}
}
int& operator[](int i)
{
if( i >= SIZE )
{
cout << "索引超过最大值" <<endl;
// 返回第一个元素
return arr[0];
}
return arr[i];
}
};
int main()
{
safearay A;
cout << "A[2] 的值为 : " << A[2] <<endl;
cout << "A[5] 的值为 : " << A[5]<<endl;
cout << "A[12] 的值为 : " << A[12]<<endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
A[2] 的值为 : 2
A[5] 的值为 : 5
A[12] 的值为 : 索引超过最大值
0
类成员访问运算符->重载
类成员访问运算符( -> )可以被重载,但它较为麻烦。它被定义用于为一个类赋予”指针”行为。运算符 -> 必须是一个成员函数。如果使用了 -> 运算符,返回类型必须是指针或者是类的对象。
运算符 -> 通常与指针引用运算符 * 结合使用,用于实现”智能指针”的功能。这些指针是行为与正常指针相似的对象,唯一不同的是,当您通过指针访问对象时,它们会执行其他的任务。比如,当指针销毁时,或者当指针指向另一个对象时,会自动删除对象。
间接引用运算符 -> 可被定义为一个一元后缀运算符。也就是说,给出一个类:
class Ptr{
//...
X * operator->();
};
类 Ptr 的对象可用于访问类 X 的成员,使用方式与指针的用法十分相似。例如:
void f(Ptr p )
{
p->m = 10 ; // (p.operator->())->m = 10
}
语句 p->m 被解释为 (p.operator->())->m。同样地,下面的实例演示了如何重载类成员访问运算符 ->。
#include <iostream>
#include <vector>
using namespace std;
// 假设一个实际的类
class Obj {
static int i, j;
public:
void f() const { cout << i++ << endl; }
//const修饰的成员函数不能修改类的成员变量,但是可以修改static修饰的成员变量
void g() const { cout << j++ << endl; }
};
// 静态成员定义
int Obj::i = 10;
int Obj::j = 12;
// 为上面的类实现一个容器
class ObjContainer {
vector<Obj*> a;
public:
void add(Obj* obj)
{
a.push_back(obj); // 调用向量的标准方法
}
friend class SmartPointer;
};
// 实现智能指针,用于访问类 Obj 的成员
class SmartPointer {
ObjContainer oc;
int index;
public:
SmartPointer(ObjContainer& objc)
{
oc = objc;
index = 0;
}
// 返回值表示列表结束
bool operator++() // 前缀版本
{
if(index >= oc.a.size() - 1) return false;
if(oc.a[++index] == 0) return false;
return true;
}
bool operator++(int) // 后缀版本
{
return operator++();
}
// 重载运算符 ->
Obj* operator->() const
{
if(!oc.a[index])
{
cout << "Zero value";
return (Obj*)0;
}
return oc.a[index];
}
};
int main() {
const int sz = 10;
Obj o[sz];
ObjContainer oc;
for(int i = 0; i < sz; i++)
{
oc.add(&o[i]);
}
SmartPointer sp(oc); // 创建一个迭代器
do {
sp->f(); // 智能指针调用
sp->g();
} while(sp++);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
10
12
11
13
12
14
13
15
14
16
15
17
16
18
17
19
18
20
19
21
Week 9
Exception Handling
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。
异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。
Key Words
throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}
如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常
您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
以下是尝试除以零时抛出异常的实例:
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
捕获异常
catch 块跟在 try 块后面,用于捕获异常。您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。
try
{
// 保护代码
}catch( ExceptionName e )
{
// 处理 ExceptionName 异常的代码
}
上面的代码会捕获一个类型为 ExceptionName 的异常。如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...,如下所示:
try
{
// 保护代码
}catch(...)
{
// 能处理任何异常的代码
}
下面是一个实例,抛出一个除以零的异常,并在 catch 块中捕获该异常。
#include <iostream>
using namespace std;
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
int main ()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
由于我们抛出了一个类型为 const char 的异常,因此,当捕获该异常时,我们必须在 catch 块中使用 const char。当上面的代码被编译和执行时,它会产生下列结果:
Division by zero condition!
标准异常
C++ 标准库定义了一组异常类,我们可以在程序中使用这些异常类处理异常。它们是以父子类层次结构组织起来的,如下所示: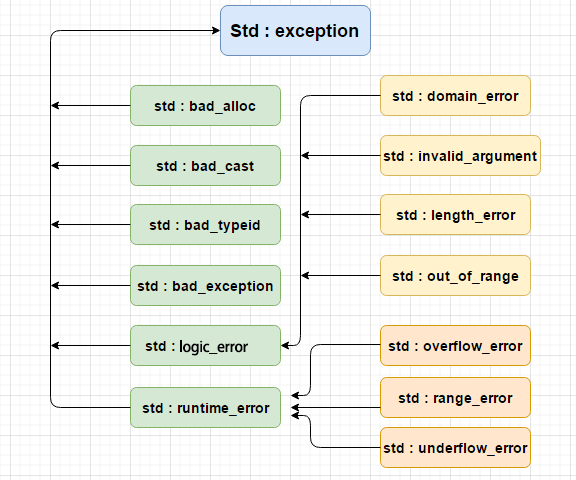
下表描述了上图中每个异常类:
|异常|描述|
|:—-|:—-|
|std::exception|该异常是所有标准 C++ 异常的父类。|
|std::bad_alloc|该异常可以通过 new 抛出。|
|std::bad_cast|该异常可以通过 dynamic_cast 抛出。|
|std::bad_exception|这在处理 C++ 程序中无法预期的异常时非常有用。|
|std::bad_typeid|该异常可以通过 typeid 抛出。|
|std::logic_error|理论上可以通过读取代码来检测到的异常。|
|std::domain_error|当使用了一个无效的数学域时,会抛出该异常。|
|std::invalid_argument|当使用了无效的参数时,会抛出该异常。|
|std::length_error|当创建了太长的 std::string 时,会抛出该异常。|
|std::out_of_range|该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator。|
|std::runtime_error|理论上不可以通过读取代码来检测到的异常。|
|std::overflow_error|当发生数学上溢时,会抛出该异常。|
|std::range_error|当尝试存储超出范围的值时,会抛出该异常。|
|std::underflow_error|当发生数学下溢时,会抛出该异常。|
定义新的异常
您可以通过继承和重载 exception 类来定义新的异常。下面的实例演示了如何使用 std::exception 类来实现自己的异常:
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的错误
}
}
这将产生以下结果:
MyException caught
C++ Exception
try catch 嵌套
异常发生后,如果一个func没有try-catch结构,直接会往调用者跑,结束该func执行流,直到找到一个自己所包括在内的try-catch结构,并匹配catch
#include <iostream>
using namespace std;
void goo(){
throw c;
}
void goo1(){
goo();
}
void goo2(){
goo1();
}
void goo3(){
try{
goo2();
}
catch(...){
cout<<"catch e in goo3"<<endl;
throw e;
}
}
int main(){
try{
goo3();
}
catch(int e){
cout<<"catch e in main"<<endl;
}
return 0;
}
输出结果:
catch e in goo3
catch e in main
比如上面这样,goo出错,goo没有try-catch,结束goo的执行流,跳回goo1;goo1没有try-catch,结束goo1的执行流,跳回goo2;goo2没有try-catch,结束goo2的执行流,跳回goo3;goo3有try-catch,而且对应的语句就在try里面,所以开始匹配catch,匹配到catch(…),里面的处理时直接throw,thow后,也立即结束goo3的执行流,跳回mainmain有try-catch,而且对应语句goo3()就在try里面,开始匹配catch,匹配到了catch(c),进行处理,没有继续throw,至此完成了整个异常处理流程。
Error-Catch of Parent-Child
子类的error可以被父类catch
这里注意,A、A*、A&都可以,但ppt上说只能是A*、A&
#include <iostream>
using namespace std;
class A{}
class B:public A{}
int main(){
try{
throw B();
}
catch(A& e){
cout<<"catch A&"<<endl;
}
catch(A* e){
cout<<"catch A*"<<endl;
}
catch(A e){
cout<<"catch A"<<endl;
}
return 0;
}
总得来说,用引用A&最好,直接用A,可能导致slice,也就是截断B
如果用A*,就得是throw new A() catch(A*), 这时候必须记得在catch里面delete(A),很不方便
Exception Specification
C++允许在函数声明的尾部指定异常,这是一个异常说明(exception specification),它指定了函数可能抛出的异常类型。异常说明的语法如下所示:
void functionName() : throw (exceptionType1, exceptionType2, ...){
// 函数的主体
};
异常使用技巧
如果构造函数出错: 比如main函数里面A a(),结果构造的时候出错了
首先,因为没有构造完成,不会在main结束后调用a的析构函数,因为根本没完成构造,那么如果A有成员 int* arr, 我们在A()里面初始化了arr = new int[100], 后来出错了,我们就没办法释放arr
所以,
- 方法1:
手动调用A() { try { … } catch(?) { delete this; throw(xxx); } }delete释放arr - 方法2: 使用两阶段,阶段一
阶段二,为数组分配内存A() { //只负责初始,比如: A.a = 2; … A.arr = NULL };A::init(){arr = new int[100];}
如果一个异常在try catch内没有被catch 捕获,也没有被throw到外面,就会导致std::terminate();。所以如果析构函数出错,最好想好处理方法,如果我们在析构函数内throw异常,会直接导致std::terminate(),终止程序



